Intel Nehalem-EP处理器首发深度评测(六)

ScienceMark v2.0 Membench
ScienceMark v2.0是一款用于测试系统特别是处理器在科学计算应用中的性能的软件,MemBenchmark是其中针对处理器缓存、系统内存而设计的功能模块,它可以测试系统内存带宽、L1 Cache延迟、L2 Cache延迟和系统内存延迟,另外还可以测试不同指令集的性能差异。
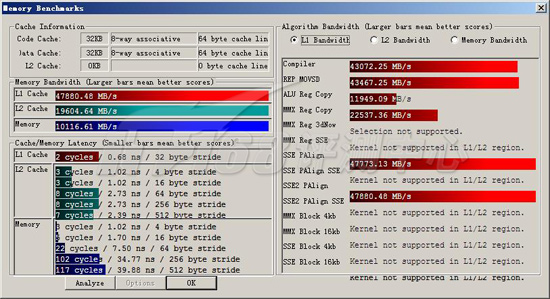
ScienceMark v2.0 Membench L1测试成绩
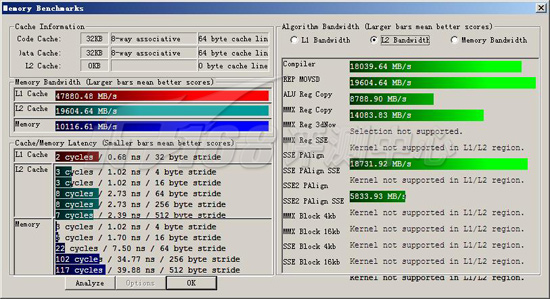
ScienceMark v2.0 Membench L2测试成绩
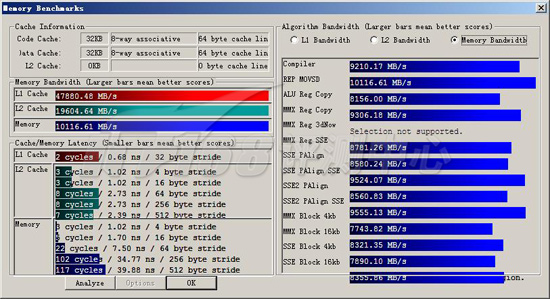
ScienceMark v2.0 Membench 内存测试成绩
首先我们进行的是ScienceMark的测试,主要考察系统的缓存和内存子系统情况。L1/L2 Cache的成绩主要是跟处理器频率相关,因为目前的处理器当中L1 Cache都是和处理器核心同频率的,而L2 Cache基本上也是??当前的处理器L2都是全速的(放置在处理器内但不在同一个芯片上的Pentium II为半速L2,而Pentium之前的处理器L2则和处理器分离,速度更低)。越快的频率,L1/L2性能就越好。而内存带宽主要由两部分相关:比较大的部分是内存架构,小部分是内存操作指令(集),例如使用最新的SSE指令集比通常的ALU指令集会得到更大的吞吐量,而不同的SSE版本性能也有不同。
| ScienceMark Membench | |||
|---|---|---|---|
| 厂商 | Intel | Intel | Intel |
| 产品型号 | Nehalem-EP Intel Gainestown Xeon X5570 2.93GHz |
AS650 AMD Shanghai Operton 2378 2.40GHz |
PowerEdge 2900 III Intel Harpertown Xeon E5430 2.66GHz |
| 内存技术参数 | 4GB R-ECC DDR3-1333 SDRAM x6 | 4GB R-ECC DDR3-1333 SDRAM x6 | 4GB R-ECC DDR3-1333 SDRAM x6 |
| L1带宽(MB/s) | 47880.48 | 48167.88 | 55376.16 |
| L2带宽(MB/s) | 19604.64 | 14314.34 | 16757.55 |
| 内存带宽(MB/s) | 10116.61 | 6672.76 | 4485.09 |
| L1 Cache Latency(ns) | |||
| 32 Bytes Stride | 2 cycles 0.68 ns |
1.25 ns | 1.13 ns |
| L1 Algorithm Bandwidth(MB/s) | |||
| Compiler | 43072.25 | 34042.63 | 25201.96 |
| REP MOVSD | 43467.25 | 34864.10 | 25467.15 |
| ALU Reg Copy | 11949.09 | 12166.94 | 13093.65 |
| MMX Reg Copy | 22537.36 | 25698.47 | 25242.19 |
| SSE PAlign | 47773.13 | 48167.40 | 52826.21 |
| SSE2 PAlign | 47880.48 | 48167.88 | 55376.16 |
| L2 Cache Latency(ns) | |||
| 4 Bytes Stride | 3 cycles 1.02 ns |
1.25 ns | 1.13 ns |
| 16 Bytes Stride | 3 cycles 1.02 ns |
1.25 ns | 1.50 ns |
| 64 Bytes Stride | 8 cycles 2.73 ns |
3.75 ns | 4.51 ns |
| 256 Bytes Stride | 8 cycles 2.73 ns |
6.25 ns | 4.51 ns |
| 512 Bytes Stride | 7 cycles 2.39 ns |
6.25 ns | 4.89 ns |
| L2 Algorithm Bandwidth(MB/s) | |||
| Compiler | 18039.64 | 11609.57 | 11880.48 |
| REP MOVSD | 19604.64 | 12140.00 | 12536.88 |
| ALU Reg Copy | 8788.90 | 9273.71 | 8577.86 |
| MMX Reg Copy | 14083.83 | 12042.45 | 13408.31 |
| SSE PAlign | 18731.92 | 14314.34 | 16719.97 |
| SSE2 PAlign | 5833.93 | 14289.88 | 16757.55 |
| Memory Latency(ns) | |||
| 4 Bytes Stride | 3 cycles 1.02 ns |
1.67 ns | 1.13 ns |
| 16 Bytes Stride | 5 cycles 1.70 ns |
5.00 ns | 4.89 ns |
| 64 Bytes Stride | 22 cycles 7.50 ns |
20.00 ns | 19.17 ns |
| 256 Bytes Stride | 102 cycles 34.77 ns |
34.58 ns | 59.77 ns |
| 512 Bytes Stride | 117 cycles 39.88 ns |
81.24 ns | 68.04 ns |
| Memory Algorithm Bandwidth(MB/s) | |||
| Compiler | 9210.17 | 2872.77 | 3178.45 |
| REP MOVSD | 10116.61 | 2887.02 | 3220.23 |
| ALU Reg Copy | 8156.00 | 2654.29 | 2789.34 |
| MMX Reg Copy | 9306.18 | 2943.85 | 2972.91 |
| MMX Reg 3dNow | - | 6631.75 | - |
| MMX Reg SSE | 8781.26 | 6672.76 | 3978.53 |
| SSE PAlign | 8580.24 | 5765.46 | 4128.59 |
| SSE PAlign SSE | 9524.07 | 6611.10 | 4390.48 |
| SSE2 PAlign | 8560.83 | 5766.87 | 4326.42 |
| SSE2 PAlign SSE | 9555.13 | 6612.42 | 4441.71 |
| MMX Block 4kb | 7743.82 | 4450.46 | 4063.30 |
| MMX Block 16kb | 8321.35 | 4677.49 | 4479.88 |
| SSE Block 4kb | 7890.10 | 4441.71 | 4074.79 |
| SSE Block 16kb | 8355.86 | 4681.34 | 4485.09 |
基本上,与处理器结合最紧密的L1,或L2(在有L3的情况下)的延迟总是跟处理器频率密集相关的,从总体测试结果来看,Nehalem-EP Xeon X5570全面强于基准平台,不过有两项数值很奇怪:SSE2 PAlign的L1测试和L2测试,这个数值明显不正常。
CineBench R10
CineBench是基于Cinem4D工业三维设计软件引擎的测试软件,用来测试对象在进行三维设计时的性能,它可以同时测试处理器子系统、内存子系统以及显示子系统,我们的平台偏向于服务器多一些,因此就只有前两个的成绩具有意义。和大多数工业设计软件一样,CineBench可以完善地支持多核/多处理器,它的显示子系统测试基于OpenGL。
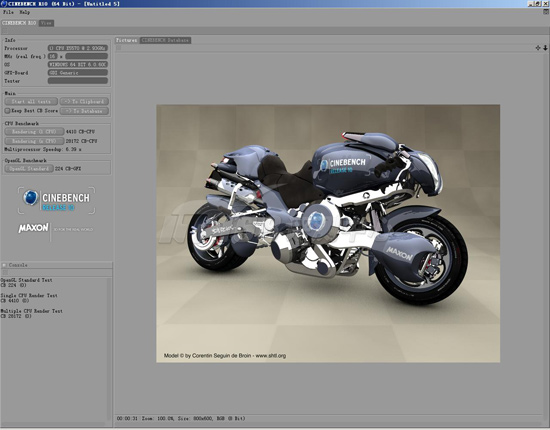
Nehalem-EP/Gainestown Xeon X5570测试成绩
|
CineBench R10 | |||
|
处理器 |
双路Intel Gainestown Xeon X5570 |
双路AMD Shanghai Operton 2378 |
双路Intel Harpertown Xeon E5430 |
| 显卡 | - | - | - |
|
CPU Benchmark | |||
| Rendering (1 CPU) | 4410 CB-CPU | 1797 CB-CPU | 2931 CB-CPU |
| Rendering (x CPU) |
28172 CB-CPU |
10734 CB-CPU |
16806 CB-CPU |
|
Multiprocessor Speedup |
6.39x |
5.97x |
5.73x |
|
OpenGL Benchmark | |||
|
OpenGL Standard |
224 CB-GFX |
98 CB-GFX |
176 CB-GFX |
Intel Nehalem-EP/Gainestown Xeon X5570测试成绩对比
单处理器的渲染性能,Xeon X5570要比Xeon E5430要高50.5%,频率上要高10.2%,架构提升很明显。
在多处理器的渲染测试中,X5570性能要高67.6%,多处理器加速比为6.39x。
Iometer 2006.07.27
我们的基准服务器采用了三块15000RPM的Seagate Cheetah 15K.5硬盘。Nehalem-EP测试样机则是用两块7200RPM Seagate Barracuda 7200.11。基准平台使用了LSI MegaRAID SAS 8408E硬件阵列卡组建了RAID 5阵列,而测试样机使用了一块集成的LSI MegaRAID SAS阵列卡。显而易见,Nehalem-EP测试样机的磁盘子系统比较糟糕。
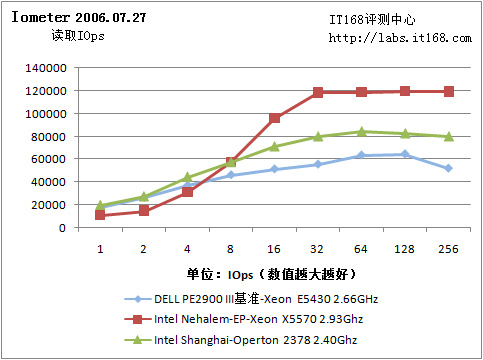
IO读
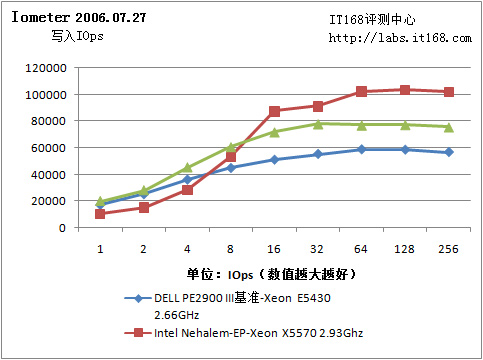
IO写
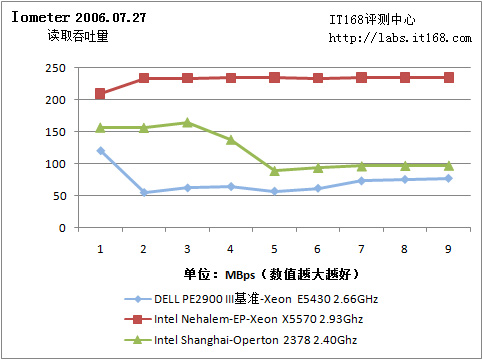
读吞吐量
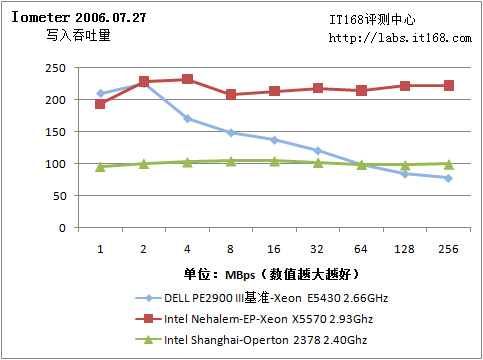
写吞吐量
由于是软阵列,阵列缓存由驱动在主内存中维护,因此512B连续读取IOps和连续吞吐量都很不错,当然……实际应用是另一回事。
NetBench v7.03
NetBench 7.03 Ent_dm.tst测试脚本模拟的是企业级文件服务器应用,它不但要求被测服务器的磁盘子系统可以提供足够的吞吐量,还需要其具有较高的IO处理能力,并且需要较为平衡的读取能力和写入能力。
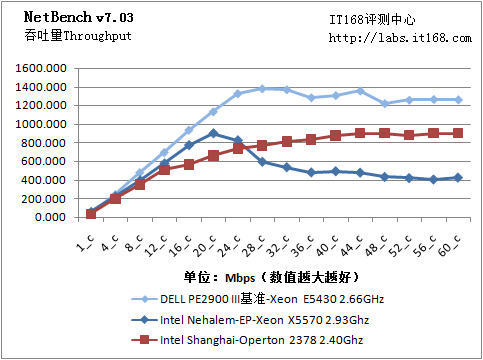
NetBench性能测试
由于是SATA软阵列??它们的曲线都表现出类似于正态分布一样:在某处具有一个波峰,两侧则逐渐下滑。Nehalem-EP测试样机的峰值吞吐量在20台测试客户机时达到,为850Mbps,此后随着客户端的增加,滑落到400Mbps附近。基准平台属于硬件阵列,Shanghai平台属于SAS Host-RAID半软半硬阵列。关于NetBench性能与处理器、内存、磁盘的关系可以看这里《评测机密:文件服务器性能提升N大要义》。
Benchmark Factory 4.6
我们在被测服务器上安装了Microsoft SQL 2005 SP1,按照测试要求建立了数据库。BF在测试之前会在数据库中生成9个表,其中包括4个500万行的表格,每行包括100字节的数据,因此每个表格容量大约是476MB,整个数据库容量为1.86GB。我们用60个客户端模拟1000个用户,在这个数据库中进行查询、添加、删除、修改等操作。
由于时间紧迫,在测试X5570的同时,我们也对另一台E5540 Nehalem-EP进行了数据库测试
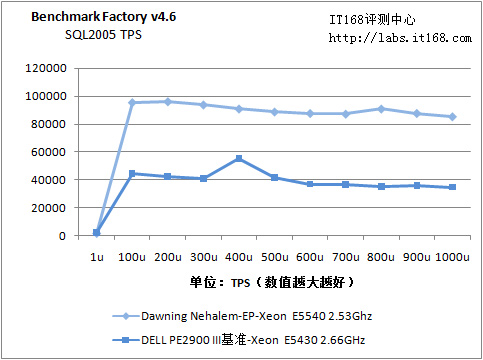
SQL2005数据库性能测试
数据库测试是一个综合性的测试,在较少客户端的时候,其性能依赖于处理器以及内存系统,在较多客户端的时候,则开始依赖于磁盘子系统。在这个测试里面,Nehalem-EP的三个优势都得以完全发挥,最终成绩非常惊人:在频率更低的情况下,平均TPS(每秒交易数)要高114%(90557.2对40397.217),提升超过了一倍以上。峰值TPS是96264.5。Nehalem真是理想的数据库平台。
为了体现出超线程对系统性能的影响,我们特地在另一台Nehalem-EP平台上作了打开/关闭超线程的测试。
|
SiSoftware Sandra Pro Business 2009 | |||
|
测试对象 |
Nehalem-EP 双路Intel Gainestown Xeon E5540 2.53GHz |
Dawning Nehalem-EP 双路Intel Gainestown Xeon E5540 2.53GHz 无超线程 | |
|
Processor Arithmetic Benchmark 处理器架构测试 | |||
| Dhrystone ALU |
129014MIPS |
130767MIPS | |
| Dhrystone ALU vs SPEED | 51.05MIPS/MHz | 51.75MIPS/MHz | |
|
Whetstone iSSE3 |
111000MFLOPS |
68158MFLOPS | |
| Dhrystone iSSE3 vs SPEED | 43.93MFLOPS/MHz | 26.97MFLOPS/MHz | |
|
Processor Multi-Media Benchmark 处理器多媒体测试 | |||
|
Multi-Media Int x16 iSSE4.1 |
269.08MPixel/s |
228.02MPixel/s | |
|
Multi-Media Int x16 iSSE4.1 vs SPEED |
106.48kPixels/s/MHz | 90.23kPixels/s/MHz | |
|
Multi-Media Float x8 iSSE2 |
206.19MPixel/s |
172.03MPixel/s | |
|
Multi-Media Float x8 iSSE2 vs SPEED |
81.60kPixels/s/MHz | 68.08kPixels/s/MHz | |
|
Multi-Media Double x4 iSSE2 |
113.93MPixel/s |
89.72MPixel/s | |
|
Multi-Media Double x4 iSSE2 vs SPEED |
45.09kPixels/s/MHz | 35.50kPixels/s/MHz | |
|
Multi-Core Efficiency Benchmark | |||
|
Inter-Core Bandwidth |
63.30GB/s |
25.88GB/s | |
|
Inter-Core Bandwidth vs SPEED |
25.65MB/s/MHz | 10.49MB/s/MHz | |
|
Inter-Core Latency (越小越好) |
22ns |
58ns | |
|
Inter-Core Latency? vs SPEED (越小越好) |
0.01ns/MHz | 0.02ns/MHz | |
|
Memory Bandwidth Benchmark 内存带宽测试 | |||
|
Int Buff‘d iSSE2 Memory Bandwidth |
9.02GB/s |
32.59GB/s | |
|
Float Buff‘d iSSE2 Memory Bandwidth |
8.90GB/s |
32.56GB/s | |
|
Memory Latency Benchmark 内存延迟测试 | |||
|
Memory(Random Access) Latency (越小越好) |
96ns |
92ns | |
|
Speed Factor (越小越好) |
59.40 |
57.90 | |
|
Internal Data Cache |
4clocks |
4clocks | |
|
L2 On-board Cache |
10clocks |
10clocks | |
|
L3 On-board Cache |
52clocks |
51clocks | |
|
Cache and Memory Benchmark 缓存及内存测试 | |||
|
Cache/Memory Bandwidth |
122.06GB/s |
120.64GB/s | |
|
Cache/Memory Bandwidth vs SPEED |
49.46MB/s/MHz | 48.89MB/s/MHz | |
|
Speed Factor (越小越好) |
22.80 |
23.10 | |
| Internal Data Cache | 398.74GB/s | 401.21GB/s | |
| L2 On-board Cache | 368.03GB/s | 362.61GB/s | |
|
.NET Arithmetic Benchmark .NET架构测试 | |||
|
Dhrystone .NET |
29299MIPS |
28774MIPS | |
|
Dhrystone .NET vs SPEED |
11.59MIPS/MHz | 11.39MIPS/MHz | |
|
Whetstone .NET |
69736MFLOPS |
44516MFLOPS | |
|
Whetstone .NET vs SPEED |
27.60MFLOPS/MHz | 17.62MFLOPS/MHz | |
|
.NET Multi-Media Benchmark .NET多媒体测试 | |||
|
Multi-Media Int x1 .NET |
53.25MPixel/s |
46.38MPixel/s | |
|
Multi-Media Int x1 .NET vs SPEED |
21.07kPixels/s/MHz | 18.35kPixels/s/MHz | |
|
Multi-Media Float x1 .NET |
23.09MPixel/s |
13.30MPixel/s | |
|
Multi-Media Float x1 .NET vs SPEED |
9.14kPixels/s/MHz | 5.26kPixels/s/MHz | |
|
Multi-Media Double x1 .NET |
45.02MPixel/s |
24.73MPixel/s | |
|
Multi-Media Double x1 .NET vs SPEED |
17.81kPixels/s/MHz | 9.79kPixels/s/MHz | |
SiSoftware Sandra对比,用蓝色标出了性能特出的项目
只有极少数的项目中,关闭超线程获得了更好的测试成绩。Nehalem-EP的超线程比起Pentium 4时代有了不少的改进,你不应该将其关闭。
评测文章导读:
Intel Nehalem-EP首发深度评测(一)
Intel Nehalem-EP首发深度评测(二)
Intel Nehalem-EP首发深度评测(三)
Intel Nehalem-EP首发深度评测(四)
Intel Nehalem-EP首发深度评测(五)
Intel Nehalem-EP首发深度评测(六)
Intel Nehalem-EP首发深度评测(七)